
深入浅出Embedding-1
写在前面
本文为阅读《深入浅出Embedding》系列读书笔记的第一篇。这本书本身并不算很精品,只能算作质量还好的科普,但是它引用的博客都写的很不错,对很多模型写得很细致,讲得很清楚,可以进去看看。
Embedding
Embedding最早是在NLP领域中被提出,前面一些部分将浅浅写一下NLP的原始内容。
传统方法
事实上,在近代的NLP问题当中,核心问题只有一个 Representation(文本表示) 。因为我们知道,文本是一种非结构化数据,是以固定的编码方式存储的一段字符串。而这样的存储方式,意味着我们无法对其进行计算。那么,早期的语言模型,主要提出了独热编码和整数编码两种对文本的表示方式。这两种方法较为基础,在此并不做更多介绍了。在本文的参考链接中,可以看到这两种方法的信息。总的来说,Embedding之前的方法,无法展示出文本之间的关联和内在信息,在可解释性上也面临较大困难。
word2vector
Word2Vec是语言模型中的一种,它是从大量文本预料中以无监督方式学习语义知识的模型,被广泛地应用于自然语言处理中。2013年横空出世。这里附上原始论文。(PDF) Efficient Estimation of Word Representations in Vector Space (researchgate.net)
省流——直接给结论
单从结果来说,word2vec就是希望,通过某种方式,用一个高维向量来表示一个单词(也可以拓展成一个词组甚至一个句子)。就是用一个数字来表示一个单词,在具体的程序中,我们给每一个不同点单词一个索引(可以理解为身份证号),然后这个唯一确定的索引对应一个唯一的高维向量。这样,这个单词就转变为高维向量,也就是计算机可计算的内容了。同时,由于将这些单词嵌入到一个高维空间中进行表示,这些词语在高维空间之中的分布可以较好地反映单词之间的内在联系,例如,大名鼎鼎的$Vector_{King}+Vector_{Man}+Vector_{Woman}\approx Vector_{Queen}$
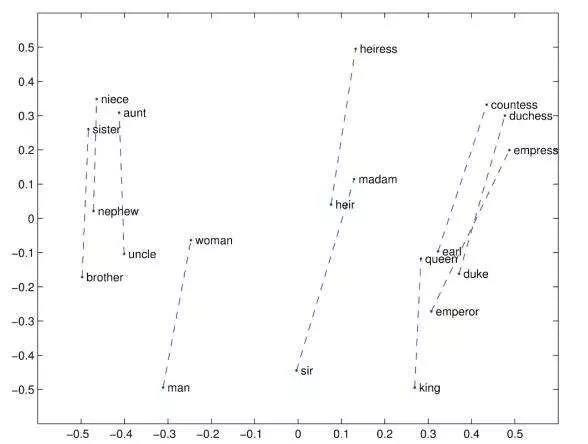
图片中,向量都是以男女做区分的一对单词。事实上,我们可以直观地看出在图上,不同性别的单词所反映的一对单词,都呈现出与男人-女人类似的分布规律,如果将他们对男人-女人的向量做类似的操作,可以得到相同的结论。
ps: 记住这个图,我最近做的一个内容和这张图所反映的现象有关,后续将进行更新。
pps: 事实上词向量的分布所反映的内容还有很多很多,比如随着欧美政治正确进入学术圈,在ACL2022的一篇论文,就描述了这样一种现象:工程师等单词在空间中的分布与男人更接近,而护士就与女性更接近。
当然这个现象,后来被成为词类比。上图是将高维向量降维到二维后进行可视化的结果,可以清晰地看出单词之间的分布,能够得出我们的结论。由于类似的结论非常符合我们人类的直觉和观感,因此Word Embedding比以前的诸多方法具有更好的解释性,即我们的词向量通过某些数学上的衡量方式,能够直接体现真实的语言之间的内在联系。
Word2vec 的 2 种训练模式
CBOW(Continuous Bag-of-Words Model)和Skip-gram (Continuous Skip-gram Model),是Word2vec 的两种训练模式。下面简单做一下解释:
CBOW
通过上下文来预测当前值。相当于一句话中扣掉一个词,让你猜这个词是什么。
Skip-gram
用当前词来预测上下文。相当于给你一个词,让你猜前面和后面可能出现什么词。
优化方法
由于Embedding大多是由onh-hot形式的稀疏矩阵得到的,为了提高速度,Word2vec 经常采用 2 种加速方式:
-
Negative Sample(负采样)
-
Hierarchical Softmax
具体算法内容考虑过些日子闲下来了写在文中,毕竟静态嵌入也在近两年逐渐被淘汰了(也可能会无限鸽下去)。可以看参考链接进行学习。
万物皆可Embedding
由于Word Embedding在NLP中取得了惊人的成果(几乎在所有榜单屠榜),因此其他一些领域也开始采用Embedding的思想进行表示学习,即将一个物体或一个行为或一种关系,由一个高维向量进行表示,然后进行机器学习和深度学习。这里出现了Item Embedding, Entity Embedding, Graph Embedding等等,被广泛地应用于推荐系统、知识图谱、自然语言处理和各种序列问题、分类问题。由于Embedding非常好地体现了被表示内容之间的内在联系,因此整个人工智能领域开始突飞猛进的发展。
事实上,任何离散的内容,都可以通过Embedding来表示。 只不过我们不能保证可解释性和模型效果。当然,在程序中,我们只需要给我们所要表示的内容,先初始化一个指定维度的向量,然后通过反向传播去更新这个向量,最终得到我们满意的Embedding层,而不是通过word2vec的方法进行训练了。
Embedding的一些问题
主要有两个问题
静态
Embedding一旦生成,就是确定的向量了,这是一个完全静态的数值。这就造成Embedding无法解决一词多义的问题,例如英文中的“Don’t trouble trouble”,可翻译为 “别烦恼了”,其中trouble这个词就属于一词多义。如果用word2vec 模型训练后,trouble只对应一个向量,显然无法区别这个trouble的两个含义。而一词多义,不论是在英语、中文还是在其他语言中,都是普遍存在的问题。不光在NLP领域,在一个物体或者一个行为,在不同环境中也会表现出不同的内容,这是静态数值无法解决的问题。
因此,在2018年开始出现预训练模型,即动态Embedding。我们将在后续文章之中介绍
超参数
Embedding要人类手动给出高维空间的维度,即你希望用一个多少维的向量表示一个单词。这个维度并不是越大越好,主流采用的数值在50-300之间。超参数是深度学习中永远的问题,主要依赖经验进行调参,并且给可解释性问题带来巨大困难。
一些哲学小思考
事实上,尽管国内很多文科人为了生存大谈人工智能的社会的改变和冲击,甚至渲染“智械危机”,但其实这坨人压根不知道Embedding是个什么东西(因为看不懂代码),可能连个多层感知机都不明白。这一点国外的学者领先国内至少30年。
不过,某种程度上Embedding背后其实反映了一个并不浪漫的事实,即在计算机的世界中,一个向量就能代表一个单词、一个行为、一个物体,区区256维的Tensor在计算机中甚至占不到1kb的存储空间,却能表示一个人(的全部)。同时,由于维度是超参数,我们可以继续追问,多少个维度(维度可以理解为特征)就能表示一个单词甚至一个人了?一个人只有256个特征或者品质吗?真的有无限可能吗?
Embedding的意义
Embedding是第一次很好地解决了用数值表示非数值化数据的问题,其优美的结论和良好的可解释性,使得其迅速风靡整个AI领域。在我看来,Embedding是推动AI发展的第一功臣,其重要性甚至超过硬件的发展对AI的影响。我们第一次初步解决了表示学习这个巨大的问题,从此之后,任何离散信息我们都可以通过Embedding的方式进行表示。甚至Embedding的出现,间接地消灭了特征工程这个传统机器学习领域最困难的部分。可以说,无论如何高度评价Embedding都不为过。具体应该结合代码,深入理解Embedding的过程和对效果的提升。


